
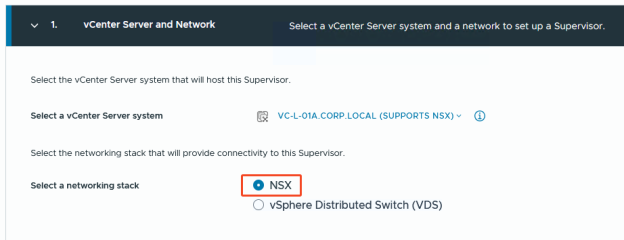
Unter vSphere 8 hat man zwei mögliche „Quests“, wenn es um das erstellen eines vSphere Supervisors geht:
- NSX
- vSphere Distributed Switch (VDS)
In diesem Post möchte ich auf die Variante mit „NSX“ eingehen, genauer gesagt NSX mit AVI als Loadbalancer, da dies seit NSX 4.1.1 möglich ist.
Eigentlich gibts dafür ja wie immer Anleitungen von Broadcom (Anleitung), aber ehrlich gesagt: wer dieser Anleitung ahnungslos folgt, der wird keinen Erfolg beim Deployment haben.
Hier noch mal mein Setup, mit dem ich es ans Fliegen bekommen habe:
- AVI 30.2.2
- vSphere 8U3e
- NSX 4.2.1.0
Los gehts!
Vorbereitung NSX
Auf NSX selbst möchte ich nicht eingehen, wir brauchen hier als Voraussetzung eine bereits konfigurierte Umgebung, sprich Overlay, T1, T0 und einen Edge Cluster.
Für den Supervisor benötigen wir allerdings zusätzlich folgende Segmente:
- ein Dummy Segment (muss beim Anlegen der NSX Cloud in AVI mitgegeben werden, wird dann aber nicht genutzt. Falls jemand eine coolere Idee hat, gerne her damit.)
- ein Management Segment (für die AVI Service Engines)
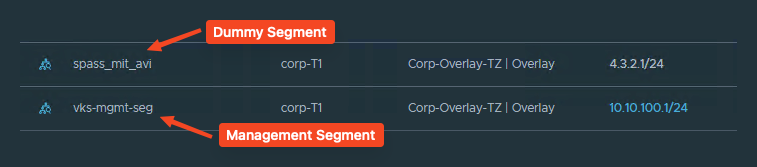
- Einen DHCP Server im Management Segment (auch für die AVI Service Engines)
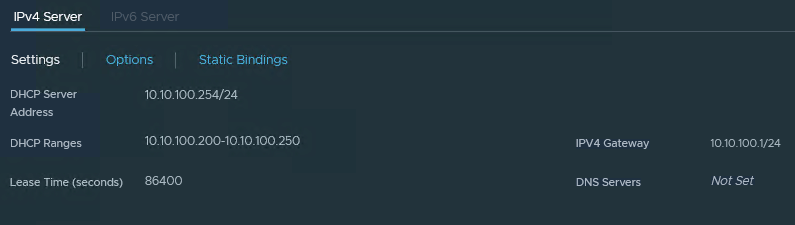
Als Subnetze habe ich mir folgende für mein Lab ausgedacht:
| Subnet | Gateway | Für was? | NSX Segment? |
|---|---|---|---|
| 4.3.2.0/24 | 4.3.2.1 | Dummy für die AVI Konfiguration | ja |
| 10.10.100.0/24 | 10.10.100.1 | Management IPs AVI Service Engines, Supervisor Nodes | ja |
| 10.10.101.0/24 | Ingress Netz aka Virtual Service IPs in AVI | nein | |
| 10.10.102.0/24 | Egress Netz aka NAT IPs, über die die Namespaces nach aussen kommunizieren | nein | |
| 10.244.0.0/20 | Netzbereich, aus dem sich die Namespaces für die Workloads bedienen (wird zusätzlich noch durch einen weiteren Prefix (bei mir /28) aufgeteilt | nein |
Vorbereitung AVI
Ich setze voraus, dass ein AVI Controller Cluster (oder auch Single Node) bereits installiert ist, bekommt man aber auch easy hin.
AVI ist ein Options-Monster, ich versuche die wirklich relevanten Settings kurz runterzureissen.
Unter „Infrastructure >> Clouds“ eine neue Cloud erstellen:
General Settings so belassen, einen Namen eintragen, die ganzen Häkchen anlassen
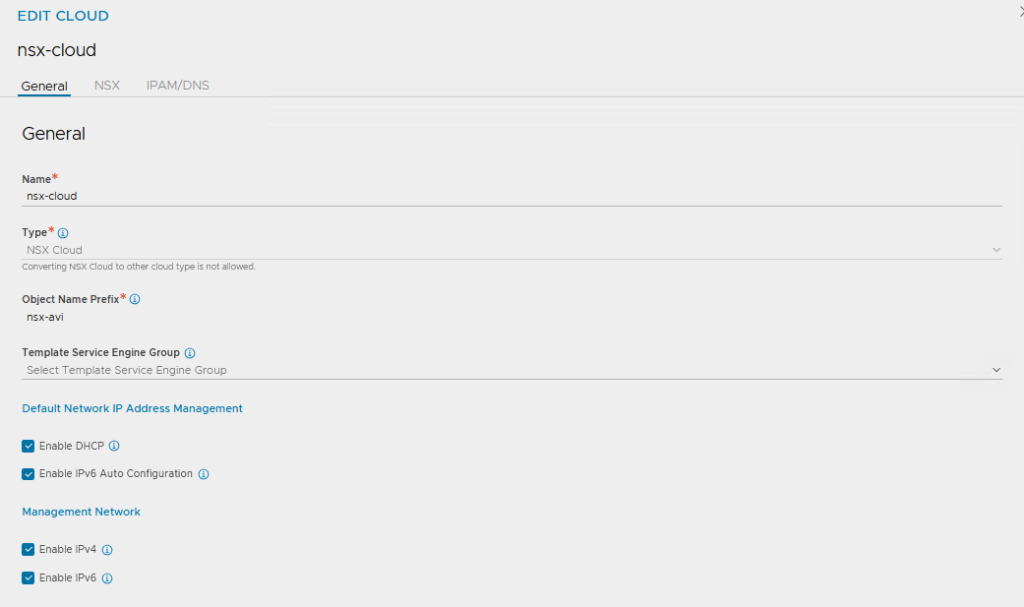
Unter „NSX“ den NSX Manager inkl. Login Credentials eintragen.
Für das Management Network die passende NSX Transport Zone, den T1 und das extra angelegte Management Segment auswählen
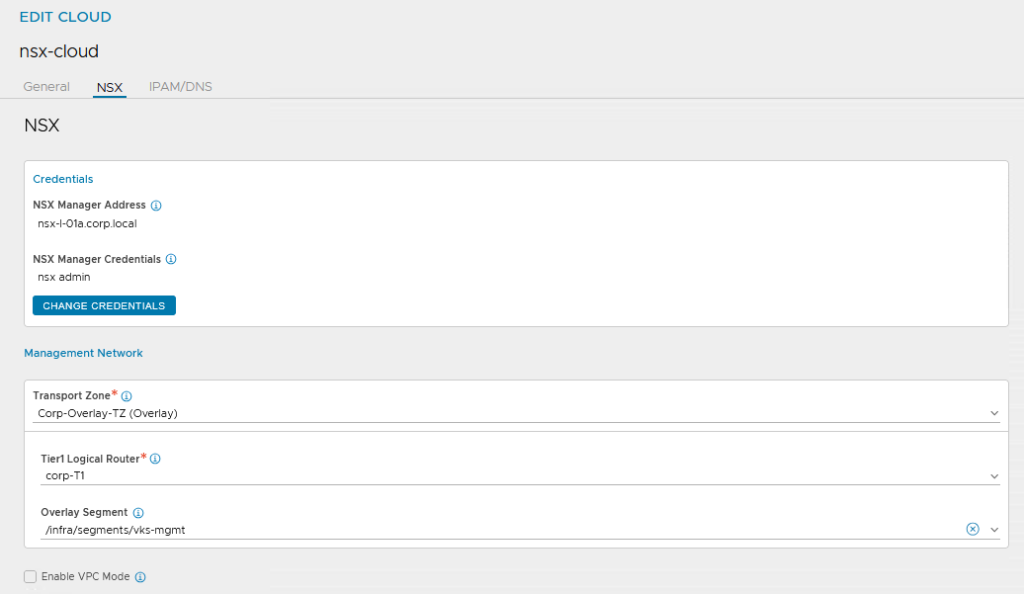
Für das „Data Network“ ist eigentlich nur die Overlay Transport Zone relevant. Den T1 und das zugehörige Segment muss man angeben, da sich die Konfiguration sonst nicht speichern lässt. NSX füllt die Segmente dann mit seinen eigenen Informationen auf.
Wichtig hierbei (weil steht nicht in der Broadcom Doku) ist das Angeben eines IPAM Profils, sonst klappts nicht mit dem Supervisor.
Achso, und dann auch noch das vCenter eintragen, bittedanke!
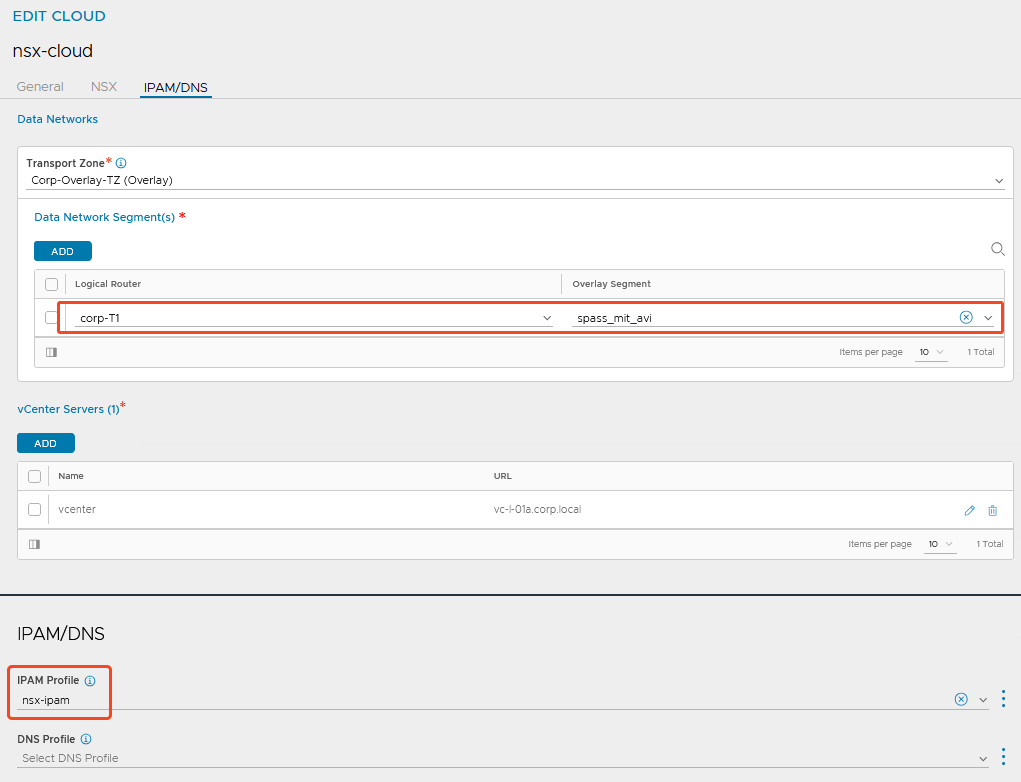
Das IPAM Profil vom Typ „Avi Vantage IPAM“ mit dem Dummy Netzwerk reicht hier aus.
NSX wird später sein eigenes Segment hier eintragen.
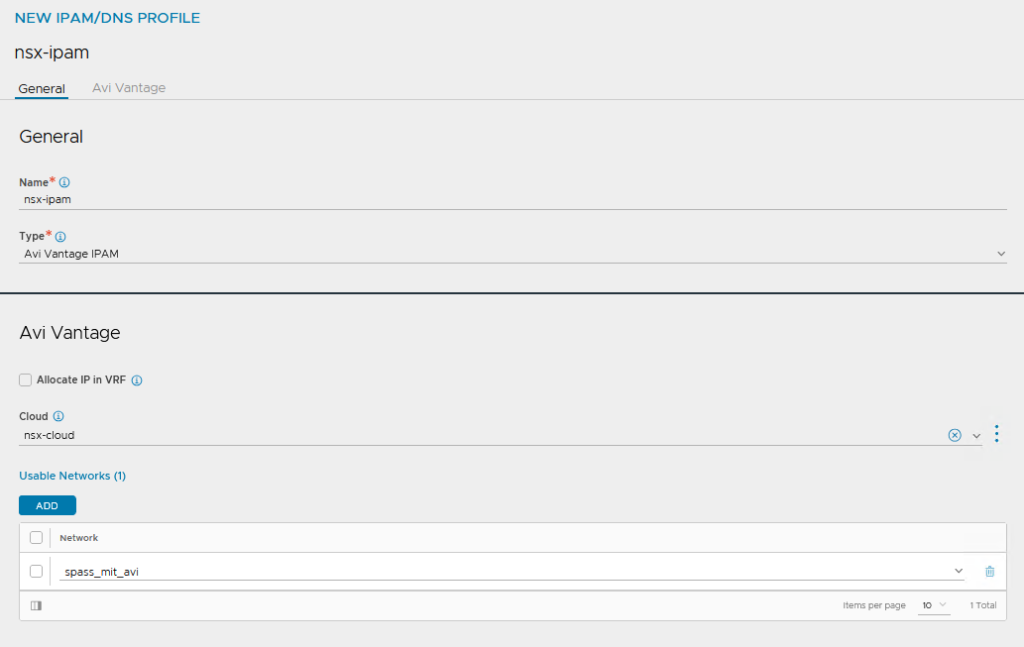
Default Service Engine Group anpassen:
Für die NSX Cloud habe ich meine Default Service Engine Group dann noch an meine „Bedürfnisse“ angepasst, das kann dann auch jeder machen wie er will.
Zertifikat anpassen:
Ansonsten habe ich noch ein eigenes Self Signed Zertifikat für die Controller erstellt und dieses für das Webinterface ausgewechselt.
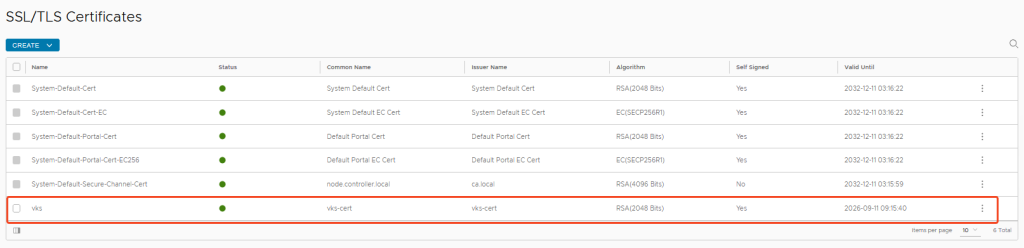
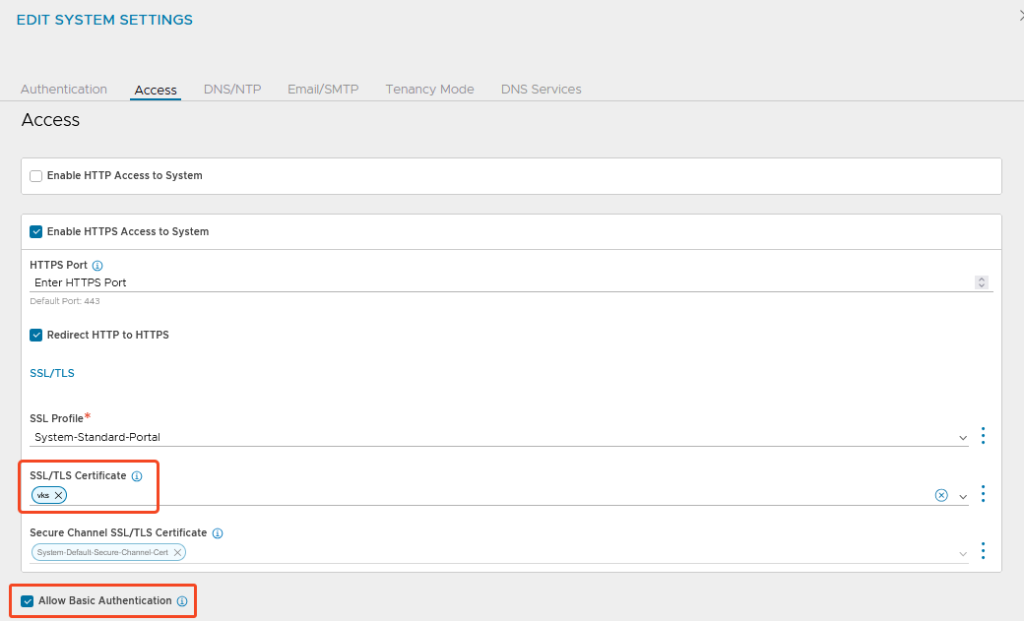
Beim Erstellen des Zertifikats darauf achten, dass alle relevanten Subject Alternative Names enthalten sind (ich packe auch gerne mal mehr rein als notwendig, bevor man am Ende was vermisst):
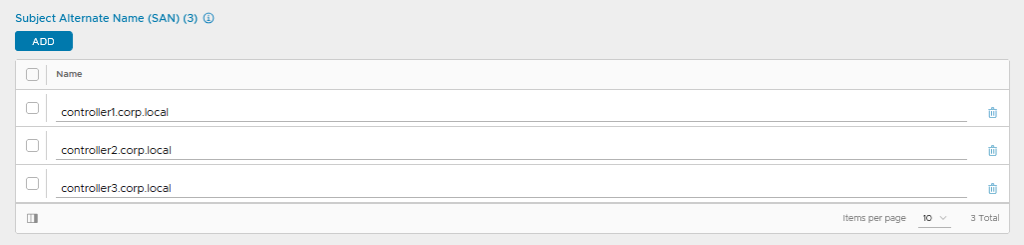
Registrierung AVI an NSX
Und jetzt kommt ein fieser Schritt, für den ich mir in „Future Releases“ Besserung erhoffe: Der AVI Controller (Cluster) muss per API Call in NSX bekannt gemacht werden (wtf?!)
Der API Call sieht dann so aus (mit den entsprechenden Stellen angepasst an die eigene Umgebung):
curl -k --location --request PUT 'https:///policy/api/v1/infra/alb-onboarding-workflow' \
--header 'X-Allow-Overwrite: True' \
--header 'Authorization: Basic ' \
--header 'Content-Type: application/json' \
--data-raw '{
"owned_by": "LCM",
"cluster_ip": "",
"infra_admin_username" : "admin",
"infra_admin_password" : "MySuperSecretSecret"
}'
Code-Sprache: PHP (php)Tipp:
Falls gerade keine Linux VM mit den passenden Tools zur Hand war, habe ich mich am existierenden vCenter bedient und hier meinen NSX User enkodiert und den API Call abgeschickt. Alle notwendigen Tools sind dort verfügbar.
#Base64 Encoding
echo -n 'user:password' | openssl base64Code-Sprache: PHP (php)Und dann mal schauen, ob die Settings passen:
curl -k -u 'user:password' --location --request GET https:///policy/api/v1/infra/sites/default/enforcement-points/alb-endpoint Code-Sprache: JavaScript (javascript)Hier sollte als Status „DEACTIVATE_PROVIDER“ stehen:
{
"connection_info" : {
"username" : "\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000",
"tenant" : "admin",
"expires_at" : "2025-05-12T16:00:09.865508+00:00",
"managed_by" : "LCM",
"status" : "DEACTIVATE_PROVIDER",
"certificate" : "...",
"is_default_cert" : true,
"enforcement_point_address" : "" ,
"resource_type" : "AviConnectionInfo"
...
}
Code-Sprache: JSON / JSON mit Kommentaren (json)vSphere Supervisor Installation
Die Vorbereitungen sind durch, also los ins Workload Management unseres vCenters, und einmal kräftig auf „Get Started“ klicken.
Schritt 1:
Ich entscheide mich für den NSX-Quest.
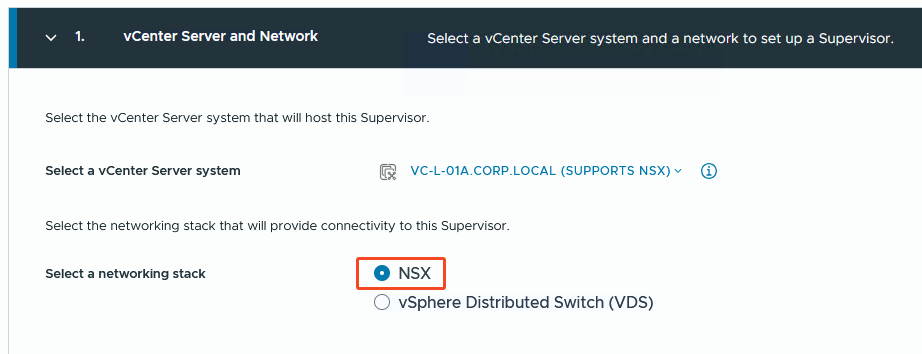
Schritt 2:
Bei mir soll es ein Cluster Deployment werden (habe leider zu wenig Cluster für das Zone Deployment 🥲 )
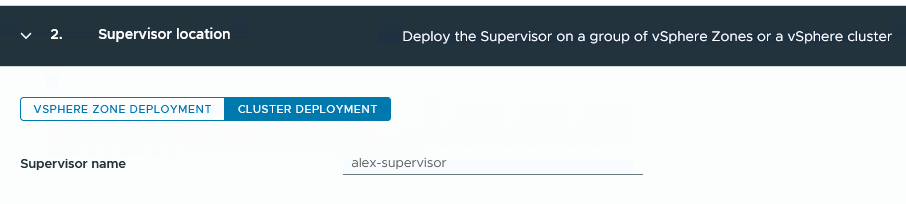
Schritt 3:
Die Auswahl der Storage Policies. Für mein Lab habe ich eine Standard VSAN Policy namens „vks-storage“ ohne viel Aufregung erstellt.
Die Ephemeral Disks Policy bezieht sich auf vSphere PODs (nutzt eh keiner) und bei der Image Cache Policy weiss ich nicht mal was gemeint ist.
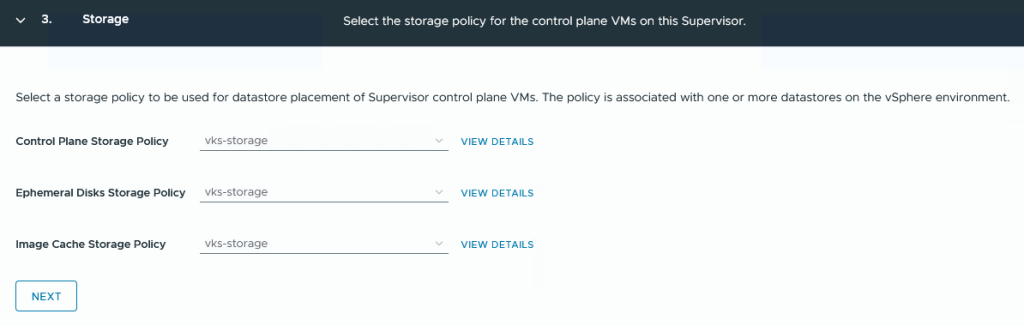
Schritt 4:
Beim Management Network entscheide ich mich für das zuvor angelegte NSX Segment „vks-mgmt-seg“.
Die Start-IP für die Supervisor VMs muss eingetragen werden, es werden 5 fortlaufende IPs verwendet (3 für die VMs, eine für „Rolling Updates“ und eine als Reserve, falls eine der VMs mal ausfallen und neu deployed werden muss)
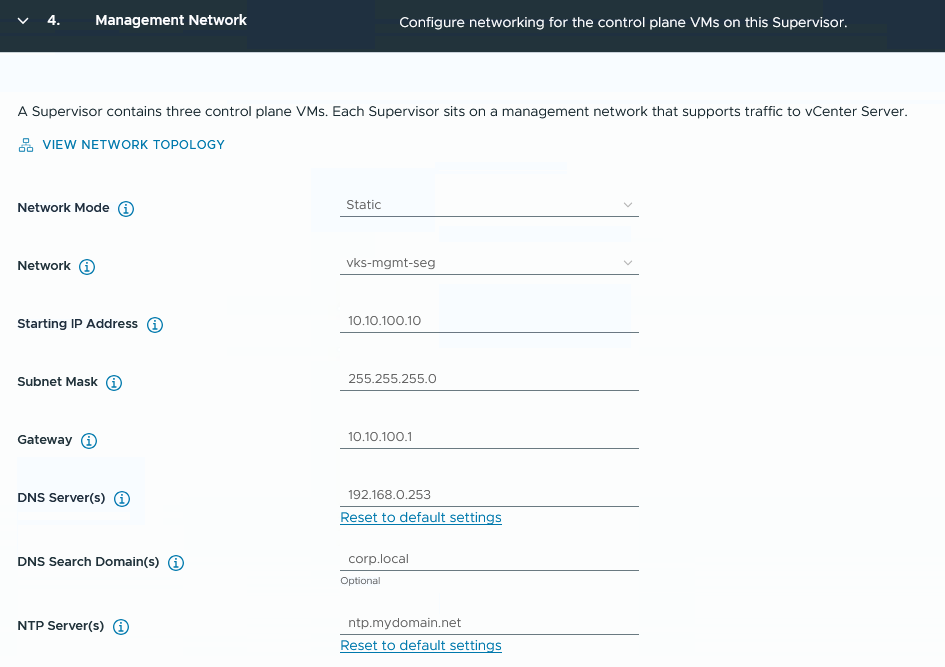
Schritt 5:
Beim Workload Netzwerk sucht man sich nun den von NSX genutzten Distributed Switch aus, den gewünschten Edge Cluster und das T0 Gateway.
Beim Namespace Network legt man fest, aus welchem IP Pool sich sämtliche Workloads (pro Namespace und Kubernetes Cluster) bedienen. Um die Größe eines „Pools“ zu definieren, dient der „Subnet Prefix“ als Limitierung (Beispiel weiter unten)
Die Ingress CIDR legt das Subnet für die öffentlichen Loadbalancer IPs fest, die AVI verwenden kann.
Die Egress CIDR dient als NAT Subnet für Namespace Services, jedem Namespace wird eine NAT Adresse zugewiesen.

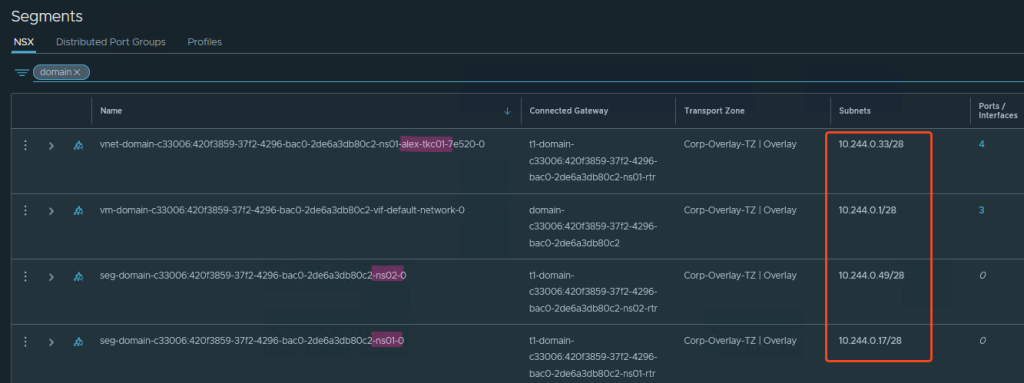
Beispiel Namespace IP Nutzung:
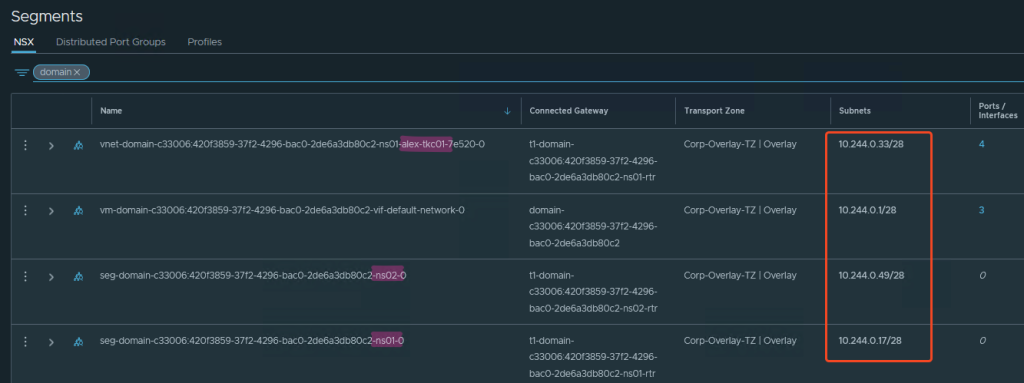
Erstelle ich einen Namespace, bekommt dieser nach meinen Einstellungen ein /28 Netz aus dem Namespace Network.
Wie auf dem Screenshot zu erkennen, erstellt NSX nun daraus Segmente. Den Namespace ns01 hatte ich zuerst erstellt, dann darin einen Tanzu Kubernetes Cluster (TKC) alex-tkc01, dann einen Namespace ns02.
Jede dieser Komponenten bekommt in meinem Fall ein Subnet mit 14 nutzbaren Adressen (/28).
Das sollte man beim Sizing beachten, da meine Workload k8s Cluster nun maximal 14 Nodes groß sein können bzw. wenn ich vSphere Pods erstellen will (😵💫?!), hier auch nach 14 Stück Schluss ist.
Innerhalb des TKC gibt es diese Limitierung nicht, hier zählt dann, was ich in meiner YAML als ServiceCIDR für den Kubernetes Cluster festlege.
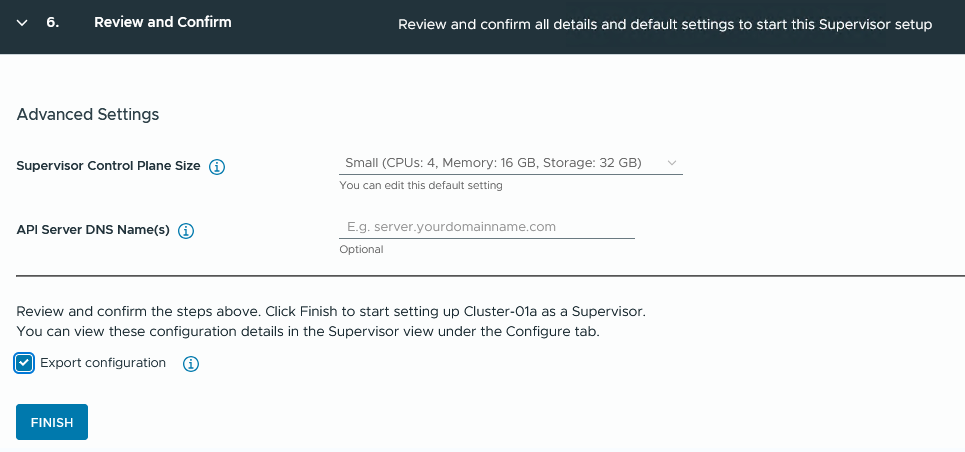
Schritt 6:
Noch schnell die Größe meiner Supervisor Nodes festgelegt, für Produktions-Umgebungen würde ich mindestens Medium wählen.
Dabei bedenken: „Größer geht immer, kleiner geht nimmer.“
Und ganz gerne auch „Export configuration„, dann gehts schneller, wenn man den Supervisor noch mal ausrollen sollte (außerdem ist es auch eine gute Doku).
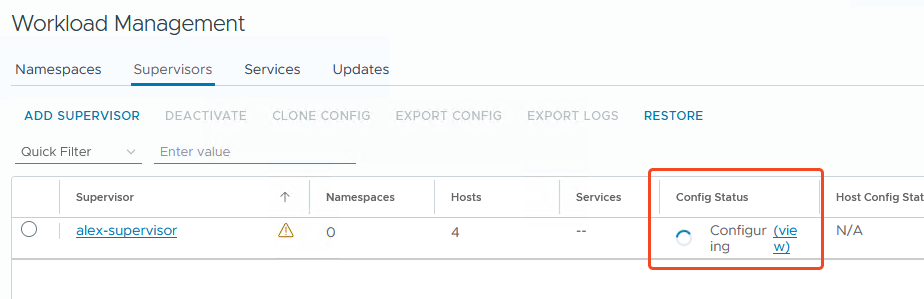
Und dann rollt er auch schon los…
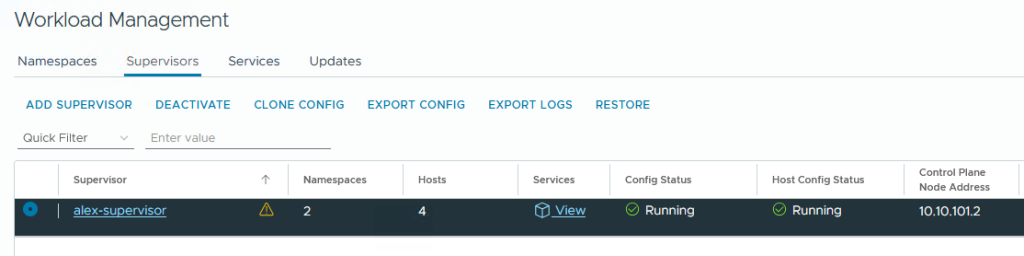
…und ist nach mehreren Minuten fertig (je nach Netzwerk, Storage etc.) 🥳
Bereit zum Workload bereitstellen!
Was geht hinter den Kulissen ab?
Im Hintergrund hat der Wizard nun die notwendigen T1, Segmente, Loadbalancer Virtual Service, Pools, NAT Regeln und was sonst noch so notwendig ist, zusammengebaut.
Das Schöne an dieser Konfiguration ist, dass sich NSX in Zukunft um die Erstellung der Workload Netze, der Loadbalancer in AVI, das Routing, etc. kümmert und eine manuelle Erstellung für Workload Netzwerke, Distributed Port Groups etc. entfällt und somit auch das Networking „innerhalb“ meiner virtuellen Umgebung stattfindet.
Hier nur ein paar Beispiele:
Automatisch erstellte T1 und Segmente in NSX:
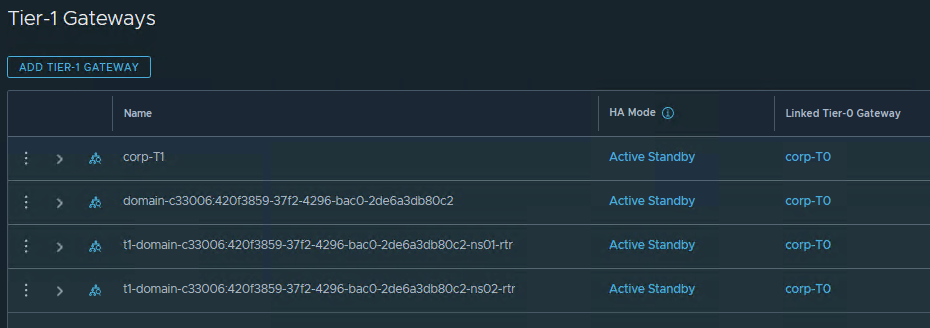
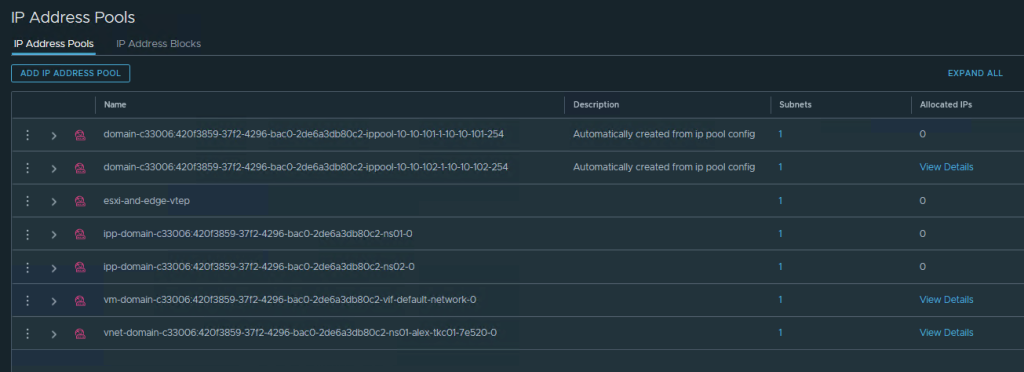
Die IPs hierzu werden aus IP Address Pools bereitgstellt:
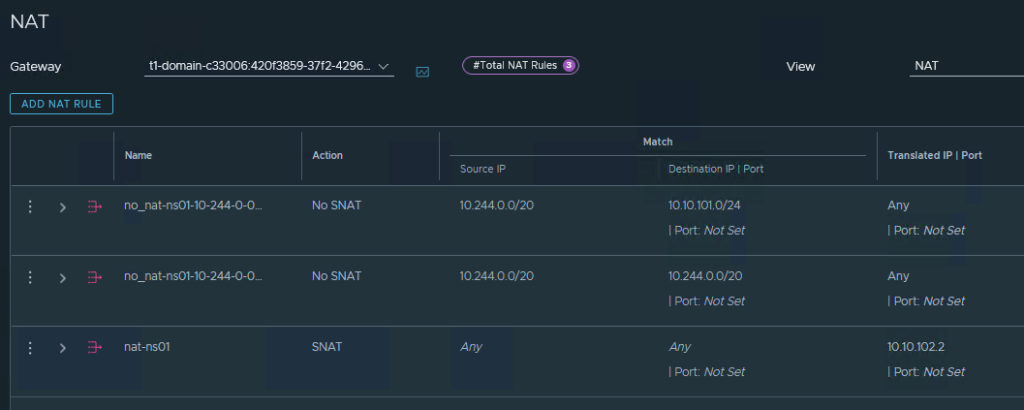
NAT Regeln in NSX für die Namespaces:
Und wenn man denkt, dass Loadbalancing nun über AVI oder k8s-interne Wege passieren, aber der Supervisor selbst stellt seine Cluster IPs über NSX Native Loadbalancer bereit:
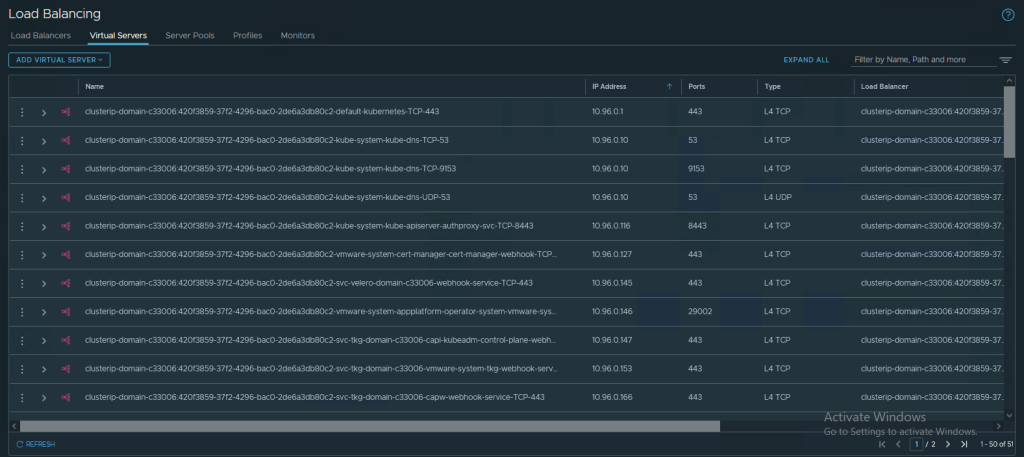
Virtual Services inkl. Pool in AVI:
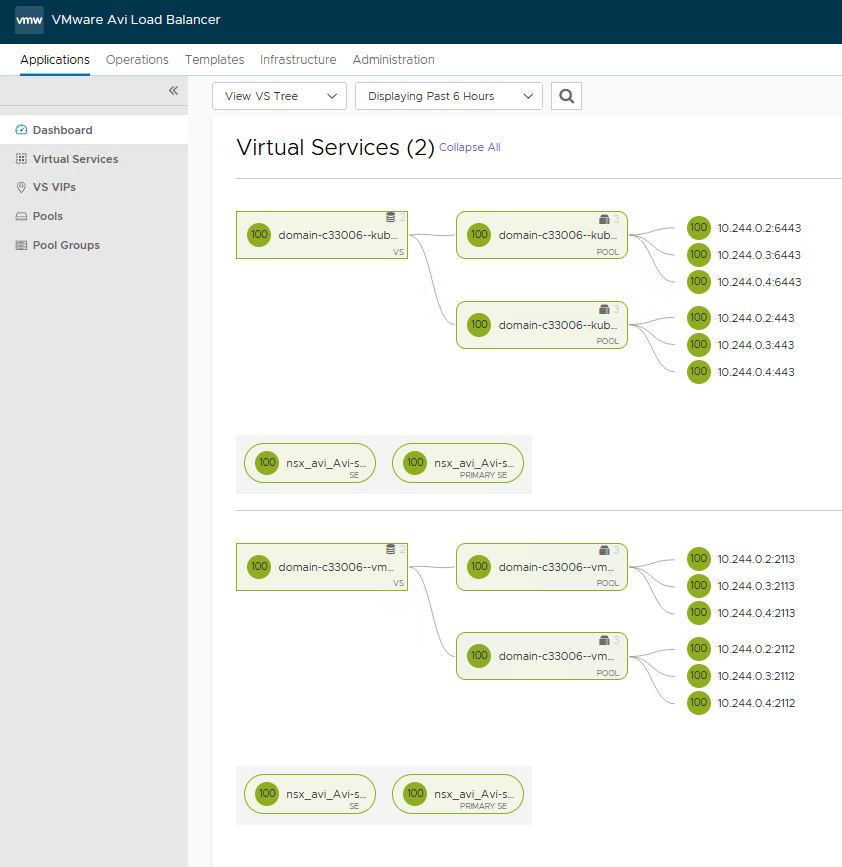
Und auch AVI bekommt seinen Network Pool, aus dem die Virtual Service IPs bezogen werden:
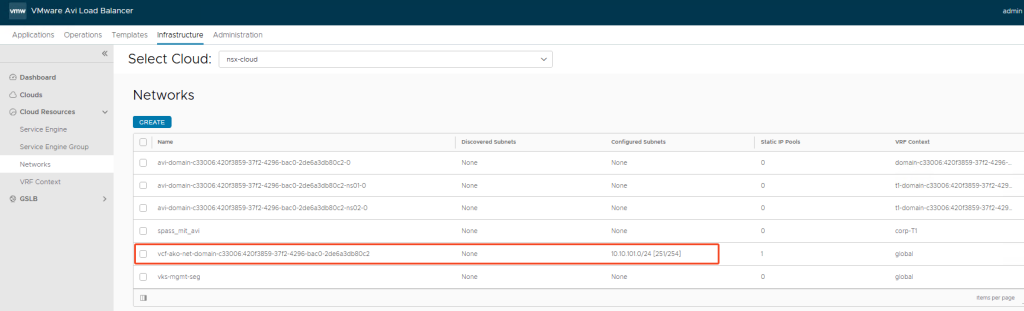
NSX Administration
Der NSX Admin denkt sich nun wahrscheinlich: „Cool, nun kann ich mit der Distributed Firewall auf Container-Ebene arbeiten!“
Dies ist leider so erstmal nicht der Fall. Der Supervisor erstellt einige Services und Gruppen, sogar einen Container Cluster, doch einen Blick ins Innenleben der Namespaces erhält man nicht. Das Regelwerk bleibt somit auf VM, Segment und Service Ebene außerhalb Kubernetes beschränkt.
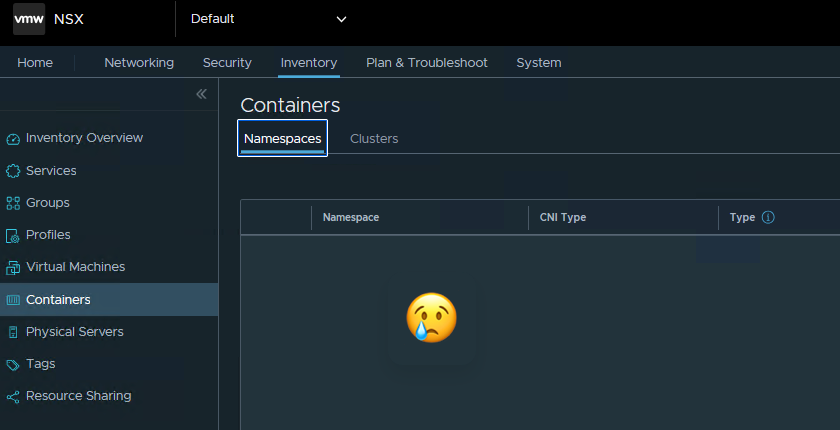
Nächster Schritt: Antrea Integration
Der Netzwerkverkehr innerhalb der Tanzu Kubernetes Cluster wird über Antrea gesteuert.
Hier gibt es die Möglichkeit einer Integration in NSX, das wird Thema in einem folgenden Blog Beitrag.